What is JASPAR?
JASPAR is a regularly maintained open-access database storing manually curated transcription factors (TF) binding profiles as position frequency matrices (PFMs). PFMs summarize occurrences of each nucleotide at each position in a set of observed TF-DNA interactions. PFMs can be transformed to probabilistic or energistic models to construct position weight matrices (PWMs) or position-specific scoring matrices (PSSMs), which can be used to scan any DNA sequence to predict TF binding sites (TFBSs). The JASPAR database provides TFBSs predicted using the profiles in the CORE collection.
The motifs in JASPAR are collected in two ways:
- Internally: de novo generated motifs, by analyzing ChIP-seq/-exo sequences using a custom motif discovery pipeline (check the code at our repository).
- Externally: motifs taken directly from other publications and/or resources.
In both cases, the selected motifs are manually curated. Specifically, our curators assess the quality of the motif and search for an orthogonal publication providing support to the motif as the bona fide motif recognized by the TF of interest (e.g., a motif found in ChIP-seq peaks looks similar to one found by SELEX-seq). The Pubmed ID associated with the orthogonal support is provided in the TF profile metadata.
JASPAR is the only database with this scope where the data can be used with no restrictions (open source). For a comprehensive review of models and how they can be used, please see the following reviews
JASPAR collections
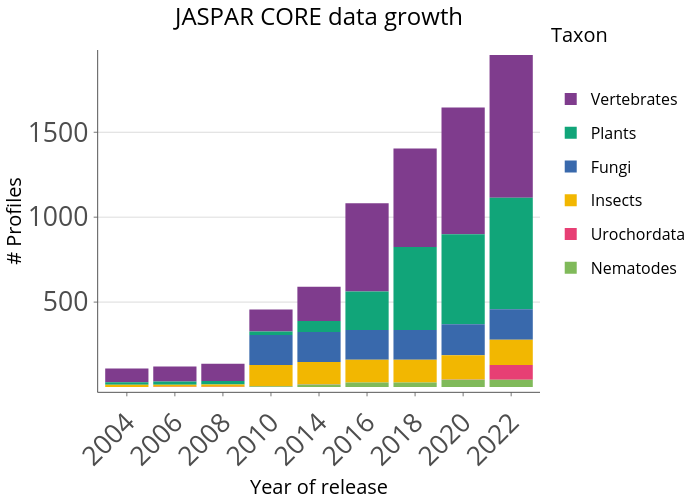
The JASPAR CORE database contains a curated, non-redundant set of profiles, derived from published collections of experimentally defined transcription factor binding sites for eukaryotes. The prime difference to similar resources (TRANSFAC, etc.) consist of the open data access, non-redundancy and quality.
When should it be used? When seeking models for specific factors or structural classes, or if experimental evidence is paramount
JASPAR CNE is a collection of 233 matrix profiles derived by Xie et al. (PNAS 2007) by clustering of overrepresented motifs from human conserved non-coding elements. While the biochemical and biological role of most of these patterns is still unknown, Xie et al. have shown that the most abundant ones correspond to known DNA-binding proteins, among them is the insulator-binding protein CTCF.
When should it be used? When characterizing of regulatory inputs in long-range developmental gene regulation in vertebrates.
The JASPAR FAM database consist of models describing shared binding properties of structural classes of transcription factors. These types of models can be called familial profiles, consensus matrices or metamodels. The models have two prime benefits: 1) Since many factors have similar target sequences, we often experience multiple predictions at the same locations that correspond to the same site. This type of models reduce the complexity of the results. 2) The models can be used to classify newly derived profiles (or project what type of structural class its cognate transcription factor belongs to).
When should it be used? When searching large genomic sequences with no prior knowledge. For classification of new user-supplied profiles.
All the PBM collections are built by using new in-vitro techniques, based on k-mer microarrays. PBM matrix models have their own database which is specialized for the data: UniPROBE. The PBM collection is the set derived by Badis et al (Science 2009) from binding preferences of 104 mouse transcription factors.
When should it be used? When characterizing of regulatory inputs in long-range developmental gene regulation in vertebrates.
All the PBM collections are built by using new in-vitro techniques, based on k-mer microarrays. PBM matrix models have their own database which is specialized for the data: UniPROBE. The PBM HLH collection is the set derived by Grove et al (Cell 2008). It holds 19 C. elegans bHLH transcription factor models.
When should it be used? Where it is important that each matrix was derived using the same protocol, focusing on bHLH factors.
All the PBM collections are built by using new in-vitro techniques, based on k-mer microarrays. PBM matrix models have their own database which is specialized for the data: UniPROBE. The PBM HOMEO collection is the set derived by Berger et al (Cell 2008) including 176 profiles from mouse homeodomain.
When should it be used? Where it is important that each matrix was derived using the same protocol, focused on homeobox factors.
The JASPAR PHYLOFACTS database consists of 174 profiles that were extracted from phylogenetically conserved gene upstream elements. See Xie et al., Systematic discovery of regulatory motifs in human promoters and 3' UTRs by comparison of several mammals., Nature 434, 338-345 (2005) and supplementary material for details.
When should it be used? The JASPAR PHYLOFACTS matrices are a mix of known and as of yet undefined motifs. They are useful when one expects that other factors might determine promoter characteristics, such as structural aspects and tissue specificity. They are highly complementary to the JASPAR CORE matrices, so are best used in combination with this matrix set.
The JASPAR POLII database consists of models describing patterns found in RNA Polymerase II (Pol II) promoters. Some of these correspond to a known protein (like the TATA box), while some has no specific interactor (like DPE). Models are taken from published literature or public databases.
When should it be used? When investigating core promoters from multicellular eukaryotes.
JASPAR SPLICE is a small collection contains matrix profiles of human canonical and non-canonical splice sites, as matching donor:acceptor pairs. It currently contains only 6 highly reliable profiles obtained from human genome made by Chong et al. 2004.
When should it be used? When analyzing splice sites and alternative splicing.
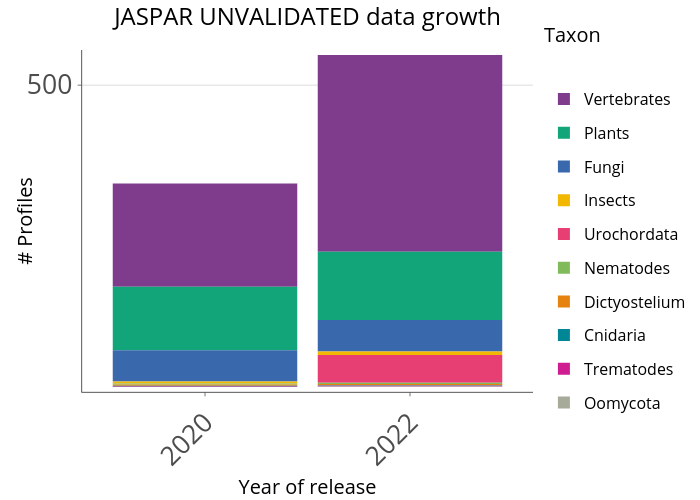
These profiles are regarded as unvalidated because our curators failed to find any orthogonal support from existing literature. We encourage the community to perform experiments and/or point us to literature that our curators missed in order to support these profiles.
When should it be used? These profiles are not non-validated so we recommend not to use them.
JASPAR CORE and UNVALIDATED data growth per release